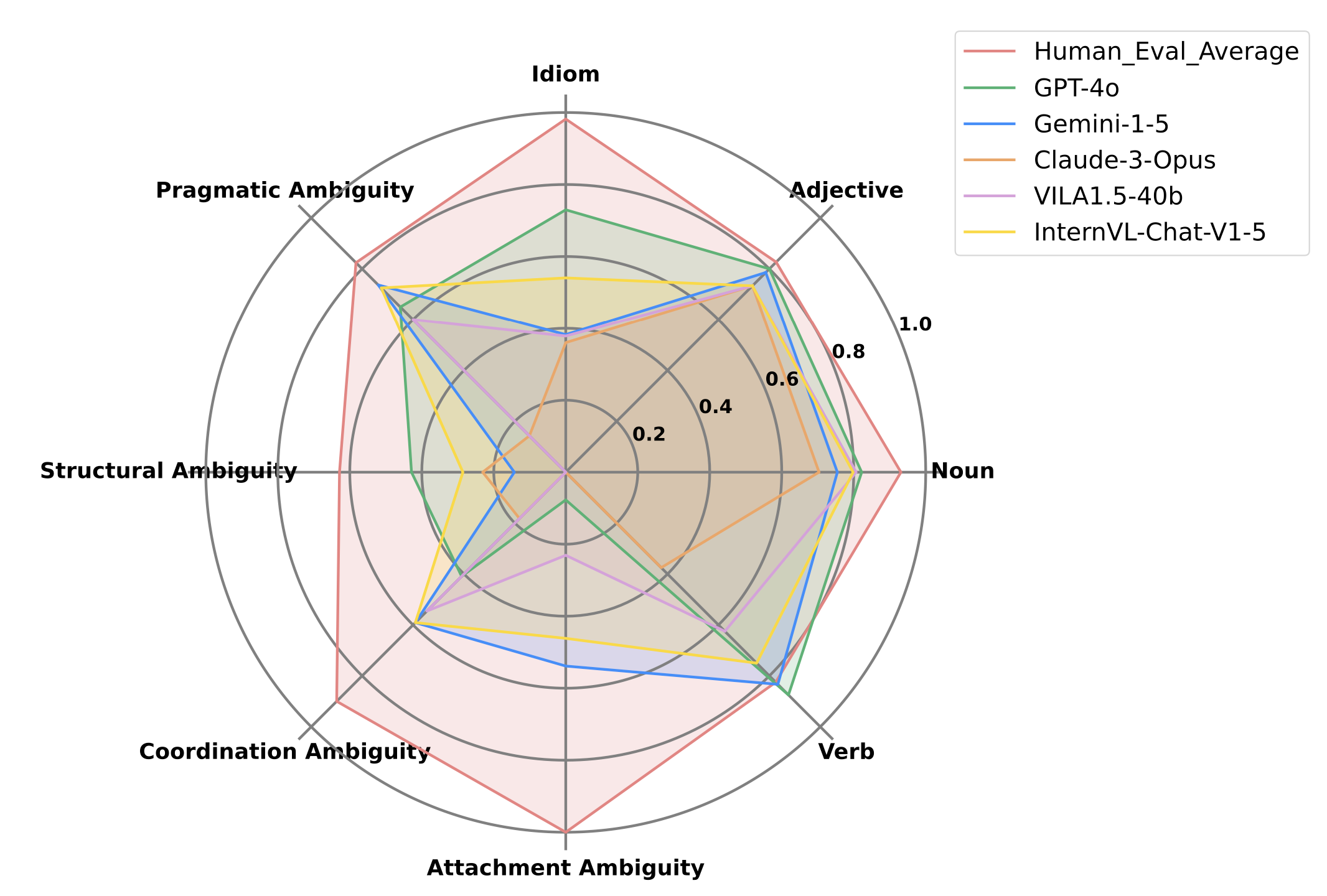
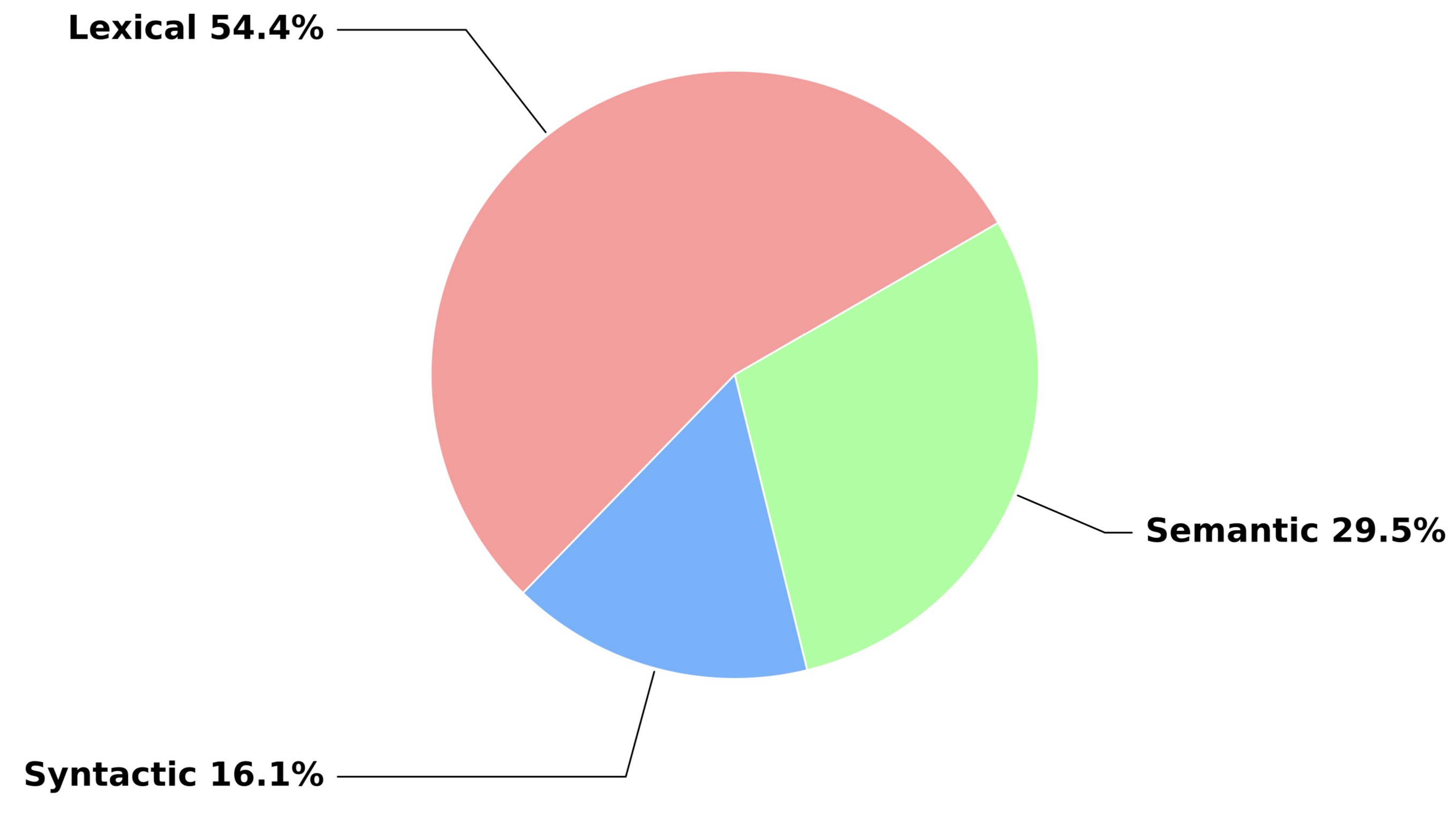
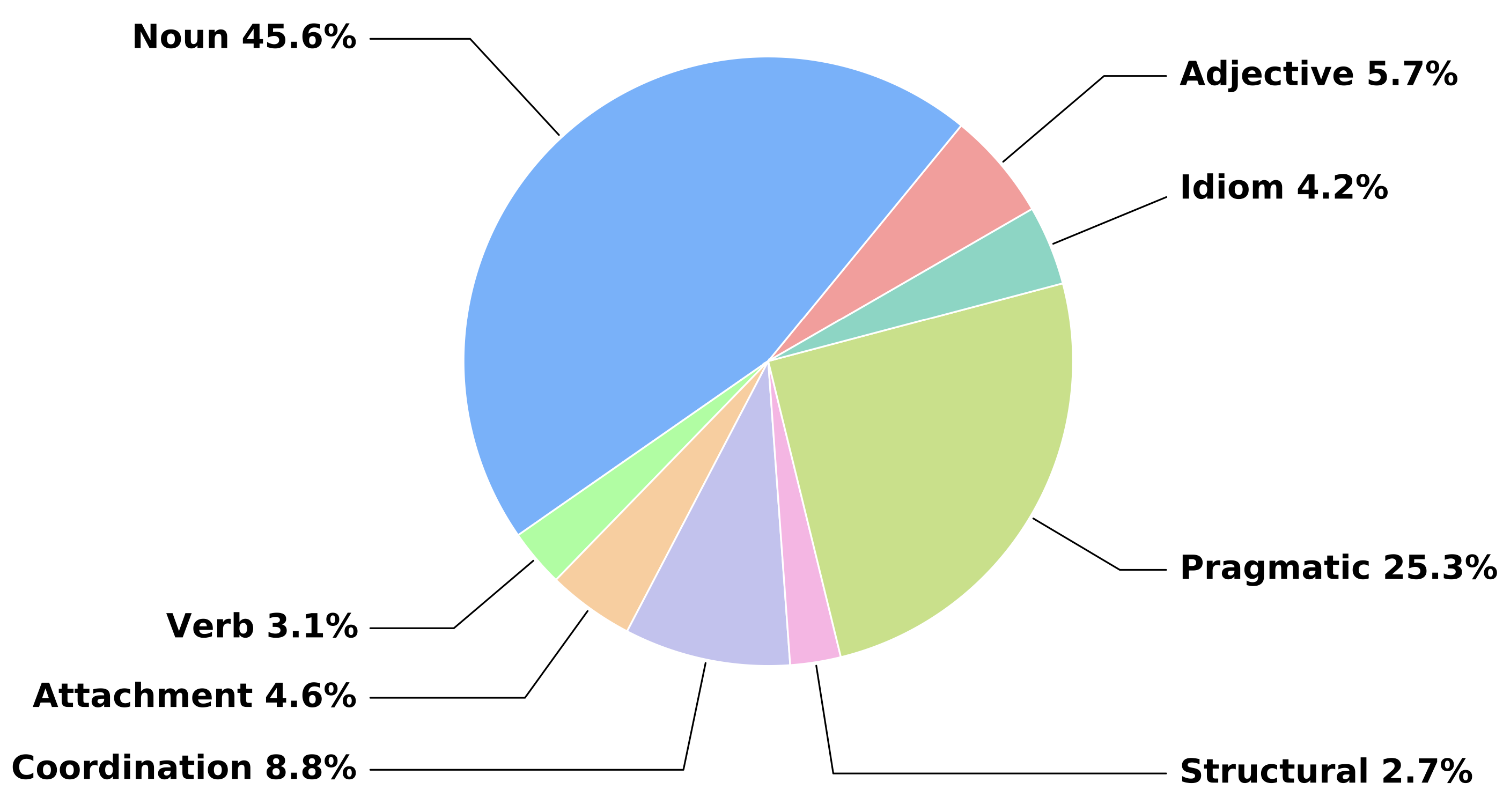
We evaluate evaluating 16 proprietary and open-sourced MLLMs.
Human Expert
Open-Source
Proprietary
| Model | Adjective (30) | Noun (238) | Verb (16) | Attachment (24) | Coordination (46) | Structural (14) | Pragmatic (132) | Idiom (22) | Lexical (284) | Syntactic (84) | Semantic (154) | Overall (522) |
| Human Best | 0.933 | 0.966 | 1.000 | 1.000 | 0.864 | 1.000 | 0.833 | 1.000 | 0.965 | 0.929 | 0.857 | 0.927 |
| Human Average | 0.827 | 0.931 | 0.825 | 1.000 | 0.900 | 0.629 | 0.824 | 0.982 | 0.914 | 0.886 | 0.847 | 0.890 |
| GPT-4o | 0.800 | 0.822 | 0.875 | 0.077 | 0.409 | 0.429 | 0.650 | 0.730 | 0.823 | 0.310 | 0.688 | 0.700 |
| InternVL-Chat-V1-5 | 0.800 | 0.832 | 0.625 | 0.385 | 0.545 | 0.143 | 0.700 | 0.541 | 0.817 | 0.429 | 0.623 | 0.697 |
| Gemini 1.5 Pro | 0.786 | 0.755 | 0.833 | 0.538 | 0.591 | 0.143 | 0.737 | 0.382 | 0.762 | 0.500 | 0.569 | 0.660 |
| GPT-4 Vision | 0.867 | 0.748 | 0.625 | 0.231 | 0.409 | 0.286 | 0.675 | 0.622 | 0.754 | 0.333 | 0.649 | 0.655 |
| VILA1.5-40b | 0.733 | 0.807 | 0.625 | 0.231 | 0.545 | 0.000 | 0.600 | 0.378 | 0.789 | 0.357 | 0.494 | 0.632 |
| LLaVA-NeXT-34B | 0.867 | 0.798 | 0.500 | 0.077 | 0.591 | 0.000 | 0.400 | 0.405 | 0.789 | 0.333 | 0.403 | 0.602 |
| HPT 1.5 Air | 0.800 | 0.756 | 0.250 | 0.231 | 0.227 | 0.000 | 0.525 | 0.595 | 0.732 | 0.190 | 0.558 | 0.594 |
| DeepSeek-VL | 0.467 | 0.697 | 0.500 | 0.231 | 0.273 | 0.000 | 0.525 | 0.378 | 0.662 | 0.214 | 0.455 | 0.529 |
| Gemini 1.0 Pro Vision | 0.692 | 0.684 | 0.400 | 0.000 | 0.318 | 0.000 | 0.405 | 0.286 | 0.674 | 0.167 | 0.347 | 0.492 |
| VILA1.5-13b | 0.400 | 0.697 | 0.125 | 0.000 | 0.136 | 0.143 | 0.375 | 0.486 | 0.634 | 0.095 | 0.429 | 0.487 |
| Yi-VL-34b | 0.733 | 0.630 | 0.250 | 0.077 | 0.136 | 0.000 | 0.450 | 0.243 | 0.620 | 0.095 | 0.351 | 0.456 |
| Cogvlm2 | 0.333 | 0.574 | 0.125 | 0.000 | 0.364 | 0.000 | 0.375 | 0.432 | 0.522 | 0.190 | 0.403 | 0.432 |
| Claude 3 Opus | 0.733 | 0.561 | 0.375 | 0.000 | 0.158 | 0.000 | 0.250 | 0.162 | 0.569 | 0.077 | 0.208 | 0.378 |
| VILA1.5-3b | 0.133 | 0.185 | 0.250 | 0.077 | 0.091 | 0.143 | 0.175 | 0.081 | 0.183 | 0.095 | 0.130 | 0.153 |
| MiniCPM-Llama3-V 2.5 | 0.000 | 0.118 | 0.250 | 0.154 | 0.136 | 0.000 | 0.225 | 0.054 | 0.113 | 0.119 | 0.143 | 0.123 |